
ENH: added pandas practical from group analysis educational sesson
Showing
- getting_started/09_pandas.ipynb 1424 additions, 0 deletionsgetting_started/09_pandas.ipynb
- getting_started/09_pandas/group_by.png 0 additions, 0 deletionsgetting_started/09_pandas/group_by.png
- getting_started/09_pandas/titanic.csv 892 additions, 0 deletionsgetting_started/09_pandas/titanic.csv
- getting_started/README.md 2 additions, 1 deletiongetting_started/README.md
getting_started/09_pandas.ipynb
0 → 100644
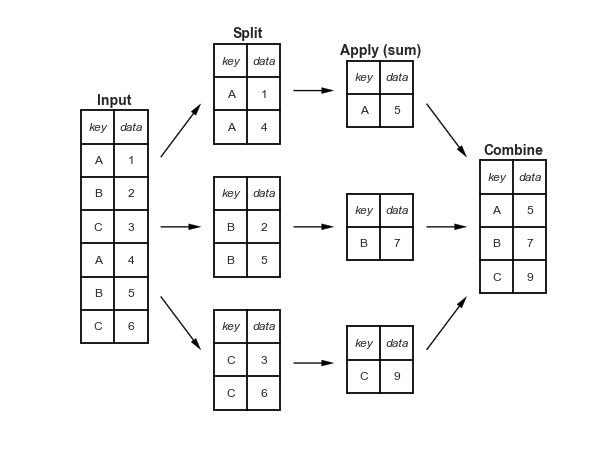
getting_started/09_pandas/group_by.png
0 → 100644
{kind=link}
24.8 KiB
getting_started/09_pandas/titanic.csv
0 → 100644
This diff is collapsed.